设计模式的复习
HTTPS(全称:Hypertext Transfer Protocol over Secure Socket Layer),是以安全为目标的HTTP通道,简单讲是HTTP的安全版。即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL
对数据进行加解密决定了它比http慢
需要进行非对称的加解密,且需要三次握手。首次连接比较慢点,当然现在也有很多的优化。
出于安全考虑,浏览器不会在本地保存HTTPS缓存。实际上,只要在HTTP头中使用特定命令,HTTPS是可以缓存的。Firefox默认只在内存中缓存HTTPS。但是,只要头命令中有Cache-Control: Public,缓存就会被写到硬盘上。 IE只要http头允许就可以缓存https内容,缓存策略与是否使用HTTPS协议无关。
http默认使用80端口,https默认使用443端口
下面就是https的整个架构,现在的https基本都使用TLS了,因为更加安全,所以下图中的SSL应该换为SSL/TLS。
下面就上图中的知识点进行一个大概的介绍。
对称加密(也叫私钥加密)指加密和解密使用相同密钥的加密算法。有时又叫传统密码算法,就是加密密钥能够从解密密钥中推算出来,同时解密密钥也可以从加密密钥中推算出来。而在大多数的对称算法中,加密密钥和解密密钥是相同的,所以也称这种加密算法为秘密密钥算法或单密钥算法。
常见的对称加密有:DES(Data Encryption Standard)、AES(Advanced Encryption Standard)、RC4、IDEA
与对称加密算法不同,非对称加密算法需要两个密钥:公开密钥(publickey)和私有密钥(privatekey);并且加密密钥和解密密钥是成对出现的。非对称加密算法在加密和解密过程使用了不同的密钥,非对称加密也称为公钥加密,在密钥对中,其中一个密钥是对外公开的,所有人都可以获取到,称为公钥,其中一个密钥是不公开的称为私钥。
非对称加密算法对加密内容的长度有限制,不能超过公钥长度。比如现在常用的公钥长度是 2048 位,意味着待加密内容不能超过 256 个字节。
数字摘要是采用单项Hash函数将需要加密的明文“摘要”成一串固定长度(128位)的密文,这一串密文又称为数字指纹,它有固定的长度,而且不同的明文摘要成密文,其结果总是不同的,而同样的明文其摘要必定一致。“数字摘要“是https能确保数据完整性和防篡改的根本原因。
数字签名技术就是对“非对称密钥加解密”和“数字摘要“两项技术的应用,它将摘要信息用发送者的私钥加密,与原文一起传送给接收者。接收者只有用发送者的公钥才能解密被加密的摘要信息,然后用HASH函数对收到的原文产生一个摘要信息,与解密的摘要信息对比。如果相同,则说明收到的信息是完整的,在传输过程中没有被修改,否则说明信息被修改过,因此数字签名能够验证信息的完整性。
数字签名的过程如下:
明文 --> hash运算 --> 摘要 --> 私钥加密 --> 数字签名
数字签名有两种功效:
一、能确定消息确实是由发送方签名并发出来的,因为别人假冒不了发送方的签名。
二、数字签名能确定消息的完整性。
注意:
数字签名只能验证数据的完整性,数据本身是否加密不属于数字签名的控制范围
对于请求方来说,它怎么能确定它所得到的公钥一定是从目标主机那里发布的,而且没有被篡改过呢?亦或者请求的目标主机本本身就从事窃取用户信息的不正当行为呢?这时候,我们需要有一个权威的值得信赖的第三方机构(一般是由政府审核并授权的机构)来统一对外发放主机机构的公钥,只要请求方这种机构获取公钥,就避免了上述问题的发生。
用户首先产生自己的密钥对,并将公共密钥及部分个人身份信息传送给认证中心。认证中心在核实身份后,将执行一些必要的步骤,以确信请求确实由用户发送而来,然后,认证中心将发给用户一个数字证书,该证书内包含用户的个人信息和他的公钥信息,同时还附有认证中心的签名信息(根证书私钥签名)。用户就可以使用自己的数字证书进行相关的各种活动。数字证书由独立的证书发行机构发布,数字证书各不相同,每种证书可提供不同级别的可信度。
浏览器默认都会内置CA根证书,其中根证书包含了CA的公钥
1、2点是对伪造证书进行的,3是对于篡改后的证书验证,4是对于过期失效的验证。
SSL为Netscape所研发,用以保障在Internet上数据传输之安全,利用数据加密(Encryption)技术,可确保数据在网络上之传输过程中不会被截取,当前为3.0版本。
SSL协议可分为两层: SSL记录协议(SSL Record Protocol):它建立在可靠的传输协议(如TCP)之上,为高层协议提供数据封装、压缩、加密等基本功能的支持。 SSL握手协议(SSL Handshake Protocol):它建立在SSL记录协议之上,用于在实际的数据传输开始前,通讯双方进行身份认证、协商加密算法、交换加密密钥等。
用于两个应用程序之间提供保密性和数据完整性。
TLS 1.0是IETF(Internet Engineering Task Force,Internet工程任务组)制定的一种新的协议,它建立在SSL 3.0协议规范之上,是SSL 3.0的后续版本,可以理解为SSL 3.1,它是写入了 RFC 的。该协议由两层组成: TLS 记录协议(TLS Record)和 TLS 握手协议(TLS Handshake)。较低的层为 TLS 记录协议,位于某个可靠的传输协议(例如 TCP)上面。
SSL与TLS握手整个过程如下图所示,下面会详细介绍每一步的具体内容:

由于客户端(如浏览器)对一些加解密算法的支持程度不一样,但是在TLS协议传输过程中必须使用同一套加解密算法才能保证数据能够正常的加解密。在TLS握手阶段,客户端首先要告知服务端,自己支持哪些加密算法,所以客户端需要将本地支持的加密套件(Cipher Suite)的列表传送给服务端。除此之外,客户端还要产生一个随机数,这个随机数一方面需要在客户端保存,另一方面需要传送给服务端,客户端的随机数需要跟服务端产生的随机数结合起来产生后面要讲到的 Master Secret 。
客户端需要提供如下信息:
服务端在接收到客户端的Client Hello之后,服务端需要确定加密协议的版本,以及加密的算法,然后也生成一个随机数,以及将自己的证书发送给客户端一并发送给客户端,这里的随机数是整个过程的第二个随机数。
服务端需要提供的信息:
客户端首先会对服务器下发的证书进行验证,验证通过之后,则会继续下面的操作,客户端再次产生一个随机数(第三个随机数),然后使用服务器证书中的公钥进行加密,以及放一个ChangeCipherSpec消息即编码改变的消息,还有整个前面所有消息的hash值,进行服务器验证,然后用新秘钥加密一段数据一并发送到服务器,确保正式通信前无误。
客户端使用前面的两个随机数以及刚刚新生成的新随机数,使用与服务器确定的加密算法,生成一个Session Secret。
ChangeCipherSpec
ChangeCipherSpec是一个独立的协议,体现在数据包中就是一个字节的数据,用于告知服务端,客户端已经切换到之前协商好的加密套件(Cipher Suite)的状态,准备使用之前协商好的加密套件加密数据并传输了。
服务端在接收到客户端传过来的第三个随机数的 加密数据之后,使用私钥对这段加密数据进行解密,并对数据进行验证,也会使用跟客户端同样的方式生成秘钥,一切准备好之后,也会给客户端发送一个 ChangeCipherSpec,告知客户端已经切换到协商过的加密套件状态,准备使用加密套件和 Session Secret加密数据了。之后,服务端也会使用 Session Secret 加密一段 Finish 消息发送给客户端,以验证之前通过握手建立起来的加解密通道是否成功。
确定秘钥之后,服务器与客户端之间就会通过商定的秘钥加密消息了,进行通讯了。整个握手过程也就基本完成了。
值得特别提出的是:
SSL协议在握手阶段使用的是非对称加密,在传输阶段使用的是对称加密,也就是说在SSL上传送的数据是使用对称密钥加密的!因为非对称加密的速度缓慢,耗费资源。其实当客户端和主机使用非对称加密方式建立连接后,客户端和主机已经决定好了在传输过程使用的对称加密算法和关键的对称加密密钥,由于这个过程本身是安全可靠的,也即对称加密密钥是不可能被窃取盗用的,因此,保证了在传输过程中对数据进行对称加密也是安全可靠的,因为除了客户端和主机之外,不可能有第三方窃取并解密出对称加密密钥!如果有人窃听通信,他可以知道双方选择的加密方法,以及三个随机数中的两个。整个通话的安全,只取决于第三个随机数(Premaster secret)能不能被破解。
对于非常重要的保密数据,服务端还需要对客户端进行验证,以保证数据传送给了安全的合法的客户端。服务端可以向客户端发出 Cerficate Request 消息,要求客户端发送证书对客户端的合法性进行验证。比如,金融机构往往只允许认证客户连入自己的网络,就会向正式客户提供USB密钥,里面就包含了一张客户端证书。
PreMaster secret前两个字节是TLS的版本号,这是一个比较重要的用来核对握手数据的版本号,因为在Client Hello阶段,客户端会发送一份加密套件列表和当前支持的SSL/TLS的版本号给服务端,而且是使用明文传送的,如果握手的数据包被破解之后,攻击者很有可能串改数据包,选择一个安全性较低的加密套件和版本给服务端,从而对数据进行破解。所以,服务端需要对密文中解密出来对的PreMaster版本号跟之前Client Hello阶段的版本号进行对比,如果版本号变低,则说明被串改,则立即停止发送任何消息。
有两种方法可以恢复原来的session:一种叫做session ID,另一种叫做session ticket。
session ID的思想很简单,就是每一次对话都有一个编号(session ID)。如果对话中断,下次重连的时候,只要客户端给出这个编号,且服务器有这个编号的记录,双方就可以重新使用已有的”对话密钥”,而不必重新生成一把。
session ID是目前所有浏览器都支持的方法,但是它的缺点在于session ID往往只保留在一台服务器上。所以,如果客户端的请求发到另一台服务器,就无法恢复对话
客户端发送一个服务器在上一次对话中发送过来的session ticket。这个session ticket是加密的,只有服务器才能解密,其中包括本次对话的主要信息,比如对话密钥和加密方法。当服务器收到session ticket以后,解密后就不必重新生成对话密钥了。
目前只有Firefox和Chrome浏览器支持。
https实际就是在TCP层与http层之间加入了SSL/TLS来为上层的安全保驾护航,主要用到对称加密、非对称加密、证书,等技术进行客户端与服务器的数据加密传输,最终达到保证整个通信的安全性。
*参考文章数字证书的基础知识HTTPS科普扫盲帖和安全有关的那些事OpenSSL 与 SSL 数字证书概念贴基于OpenSSL自建CA和颁发SSL证书聊聊HTTPS和SSL/TLS协议SSL/TLS协议运行机制的概述图解SSL/TLS协议大型网站的 HTTPS 实践SSL/TLS原理详解扒一扒HTTPS网站的内幕白话解释 OSI模型,TLS/SSL 及 HTTPSOpenSSL HeartBleed漏洞原理漫画图解*
单元测试
对mvp框架的理解,有什么优点?
activity的四种启动模式: standard(标准模式)、singtop 栈顶模式 singtask、singinstance
Activity生命周期? oncreate—>onrestart—>onstart—>onresume—>onpause—>onstop—>ondestory
Service生命周期?这里要注意service有两种启动方式,startService()和bindService():
oncreate—>onstartcommand—>ondestory
oncreate—>onbind—>onunbind—>ondestory
理解Activity,View,Window三者关系?
activity 启动的时候会初始化一个Window,准确的说是phonewindow,这个phonewindow有一个ViewRoot,这个ViewRoot是一个view或viewgroup,是最初始的根布局,“ViewRoot”通过addView方法来一个个的添加View。比如TextView,Button等,这些View的事件监听,是由WindowManagerService来接受消息,并且回调Activity函数。比如onClickListener,onKeyDown等。
View的绘制流程?
Touch事件传递机制?
界面性能优化?
java内存的分配:
四种引用类型的介绍:
造成内存泄漏的几个原因:
ANR
Threadlocal 怎么使用?
设计模式
算法
handle 原理
http tcp ip 怎么理解
对链表结构的理解?
对于集合的理解:
collection与map的区别?
对于多线程的理解?
android中的四大组件?
android序列化的方式 ,原理有什么区别?
线程池是什么?
位移?
xml/json解析数据区别?
怎么加载一张大图片?
android 消息推送原理?
webview的bug?
奔溃日志的处理?
在Wiredrive上,我们做了很多的Code Review。在此之前我从来没有做过,这对于我来说是一个全新的体验,下面来总结一下在Code Review中做的事情以及说说谈论Code Review的最好方式。
简单的说,Code Review是开发者之间讨论修改代码来解决问题的过程。很多文章谈论了Code Review的诸多好处,包括知识共享,代码的质量,开发者的成长,却很少讨论审查什么、如何审查。
###审查的内容
####体系结构和代码设计
单一职责原则:一个类有且只能一个职责。我通常使用这个原则去衡量,如果我们必须使用“和”来描述一个方法做的事情,这可能在抽象层上出了问题。
开闭原则如果是面向对象的语言,对象对可扩展开放、对修改关闭。如果我们需要添加另外的内容会怎样?
代码复用:根据“三振法”,如果代码被复制一次,虽然如喜欢这种方式,但通常没什么问题。但如果再一次被复制,就应该通过提取公共的部分来重构它。
换位考虑,如果换位考虑,这行代码是否有问题?用这种模式是否可以发现代码中的问题。
用更好的代码: 如果在一块混乱的代码做修改,添加几行代码也许更容易,但我建议更进一步,用比原来更好的代码。
潜在的bugs:是否会引起的其他错误?循环是否以我们期望的方式终止?
错误处理:错误确定被优雅的修改?会导致其他错误?如果这样,修改是否有用?
效率: 如果代码中包含算法,这种算法是否是高效? 例如,在字典中使用迭代,遍历一个期望的值,这是一种低效的方式。
####代码风格
方法名: 在计算机科学中,命名是一个难题。一个函数被命名为==get_message_queue_name==,但做的却是完全不同的事情,比如从输入内容中清除html,那么这是一个不准确的命名,并且可能会误导。
值名:对于数据结构,==foo== or ==bar== 可能是无用的名字。相比==exception==, ==e==同样是无用的。如果需要(根据语言)尽可能详细,在重新查看代码时,那些见名知意的命名是更容易理解的。
函数长度: 对于一个函数的长度,我的经验值是小于20行,如果一个函数在50行以上,最好把它分成更小的函数块。
类的长度:我认为类的长度应该小于300行,最好在100内。把较长的类分离成独立的类,这样更容易理解类的功能。
文件的长度: 对于Python,一个文件最多1000行代码。任何高于此的文件应该把它分离成更小更内聚,看一下是否违背的“单一职责” 原则。
文档:对于复杂的函数来说,参数个数可能较多,在文档中需要指出每个参数的用处,除了那些显而易见的。
注释代码: 移除任何注释代码行。
####测试
####审查代码
在提交代码之前,我经常用git添加改变的文件/文件夹,然后通过git diff 来查看做了哪些修改。通常,我会关注如下几点:
和著名的橡皮鸭调试法(Rubber Duck Debugging)一样,每次提交前整体把自己的代码过一遍非常有帮助,尤其是看看有没有犯低级错误。
####如何进行Code Review
当Code Review时,会遇到不少问题,我也学会了如何处理,下面是一些方法:
####心态上
Gradle 虽然之前一直存在于Android Studio中,但是它变成热门的转折点是Android Studio成为官方开发IDE。但是,我们充分利用这个伟大的构建自动化系统了吗?
使用gradle,会自动生成一个BuildConfig类文件并且我们有能力在它里面生成额外的字段。这对于像配置服务器URL和切换开关这类功能都是非常有用的。
|
|
BuildConfig.TWITTER_TOKEN, BuildConfig.REPORT_CRASHES 和 BuildConfig.API_URL 都是能够通过BuildConfig这个final class访问的。(后面两个变量的值根据构建类型而不同)
这个可以让你有release和debug两个版本的应用在同一时间被安装(记住android不让你安装相同的包名的不同的应用)!
你可以在你的崩溃报告工具中通过不同的版本名来过滤问题/崩溃。
通过查看应用名称很容易发现你当前运行的是哪一个!
|
|
Android要求所有的应用被安装之前用一个证书进行数字签名。Android使用这个证书识别应用的作者,尽管这是一些不应该让其它人看见的敏感信息。
你永远不应该提交这种信息到版本控制工具上。
一些人认为你应该有一个本地配置文件或者甚至是一个全局~/.gradle/build.gradle使用这些值,但如果你正在做连续的集成/部署并且你没有自己专门的CI服务器,在你的版本控制器上不应该有任何带着证书用纯文本的方式展示的这种文件。
|
|
通过这种方式我可以将敏感信息提交到我自己的CI服务器而不用担心提交到公司的CVS上。
把你的版本信息从逻辑组件分离出来并且分别管理它们。不用再烦恼如何放置正确的版本号与版本名称。
|
|
|
|
现在有两个变量可以用,BuildConfig.GIT_SHA 和BuildConfig.BUILD_TIME ,这在绑定提交/构建时间到log里面是非常方便的!
对于快速部署只需要创建一个叫做dev的flavour 并且设置minSdkVersion 为21.通过这么做需要注意的是你不会得到你真正的minSdk的linting检查提示,显而易见的是这仅仅会被用于日常工作而不是发布。这会允许Android gradle插件预编译(pre-dex) 每个module并且编译的APK可以在Android Lollipop( 5.0)及以上进行测试而不需要花费dex 合并处理时间。
|
|
一个小窍门因此我们可以看到android单元测试它们发生的日志结果。
|
|
现在运行你的测试它们将输出类似于这样的东西:
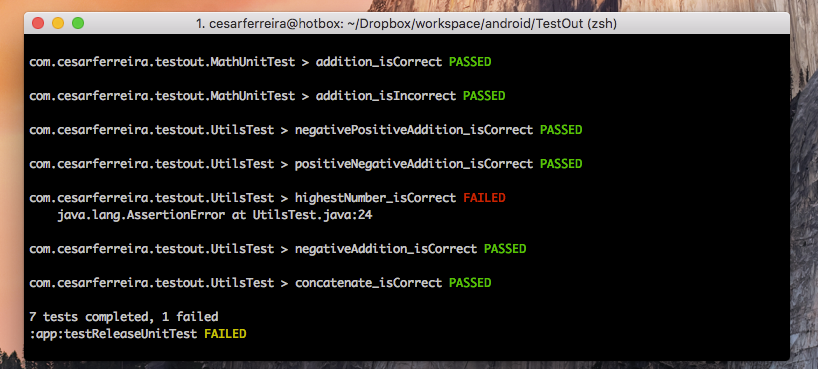
单元测试日志输出
一个有组织地方式使用它:
|
|
当你开始写android时,我们所学到的是不能直接向Activities和Fragments传递对象,我们不得不借助Intent或者Bundle来传递它们。
当我们看api文档的时候,我们认识到有两种选择,我们的对象要么是Parcelable或者Serializable型,作为一个java开发者,我们已经知道Serializable的机制,那为什么还要去研究Parcelable呢?
为了回答这个问题,我们来看两个方法。
####Serializable,简洁的鼻祖####
|
|
仅仅需要在它和它的子类上实现Serializable接口就能完成一个漂亮的Serializable功能,他是一个标记接口,意味着不需要实现任何方法,java虚拟机将简单高效地完成序列化工作。
这里面有个问题就是这种序列化是通过反射机制从而削弱了性能,这种机制也创建了大量的临时对象从而引起GC频繁回收调用资源。
####Parcelable, 速度之王####123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172// access modifiers, accessors and regular constructors ommited for brevityclass ParcelableDeveloper implements Parcelable { String name; int yearsOfExperience; List<Skill> skillSet; float favoriteFloat; ParcelableDeveloper(Parcel in) { this.name = in.readString(); this.yearsOfExperience = in.readInt(); this.skillSet = new ArrayList<Skill>(); in.readTypedList(skillSet, Skill.CREATOR); this.favoriteFloat = in.readFloat(); } void writeToParcel(Parcel dest, int flags) { dest.writeString(name); dest.writeInt(yearsOfExperience); dest.writeTypedList(skillSet); dest.writeFloat(favoriteFloat); } int describeContents() { return 0; } static final Parcelable.Creator<ParcelableDeveloper> CREATOR = new Parcelable.Creator<ParcelableDeveloper>() { ParcelableDeveloper createFromParcel(Parcel in) { return new ParcelableDeveloper(in); } ParcelableDeveloper[] newArray(int size) { return new ParcelableDeveloper[size]; } }; static class Skill implements Parcelable { String name; boolean programmingRelated; Skill(Parcel in) { this.name = in.readString(); this.programmingRelated = (in.readInt() == 1); } void writeToParcel(Parcel dest, int flags) { dest.writeString(name); dest.writeInt(programmingRelated ? 1 : 0); } static final Parcelable.Creator<Skill> CREATOR = new Parcelable.Creator<Skill>() { Skill createFromParcel(Parcel in) { return new Skill(in); } Skill[] newArray(int size) { return new Skill[size]; } }; int describeContents() { return 0; } }}
按照google工程师的说话,这段代码将跑起来非常快,其中一个原因是运用真实的序列化处理代替反射,为了完成这个目的代码也做了大量的优化。
然而,显而易见的是实现Parcelable接口并不是无成本的,创建了大量的引入代码从而导致整个类变得很重同时加大了维护成本。
####Speed Tests####
当然,我们想知道Parcelable到底有多快
测试步骤
1:模拟这个操作通过Bundle的writeToParcel(Parcel, int)向Activity传递对象,然后观察它。
2:循环这个操作1000次。
3:大概模拟10次,观察内存回收情况,以及app的cpu使用率,等等。
4:这个被测试的对象分别是SerializableDeveloper和ParcelableDeveloper。
5:在多种机型和版本上做测试
LG Nexus 4 - Android 4.2.2
Samsung Nexus 10 - Android 4.2.2
HTC Desire Z - Android 2.3.3
测试结果:
Nexus 10
Serializable: 1.0004ms, Parcelable: 0.0850ms - 10.16x improvement.
Nexus 4
Serializable: 1.8539ms - Parcelable: 0.1824ms - 11.80x improvement.
Desire Z
Serializable: 5.1224ms - Parcelable: 0.2938ms - 17.36x improvement.
分析:
Parcelable比Serializable速度快10倍,在Nexus 10测试过程中得到了有趣的结果,仅仅通过1毫秒就完成了整个的序列化与反序列化过程。
总结:
假如你想成为一个好的码农,找个时间替换成Parcelable吧,他将提高十倍的速度并且用更少的资源。
然而,在大部分的案例里,这种缓慢的Serializable序列化过程并没有被注意到,有时候仅仅是为了成本比较低才会使用它但是要记住Serialization是要付出很大的代价的,所以还是尽量少使用这种方式。
假如你想传递成百上千的序列化对象,整个序列化的过程可能会超过一秒,当你对手机屏幕进行横竖屏切换将感觉有点延迟。
Snackbar是design support library中另一个组件,使用Snackbar我们可以在屏幕底部(大多时候)快速弹出消息,它和Toast非常相似,但是它更灵活一些。
Snackbar基本上继承了和Toast一样的方法和属性,例如LENGTH_LONG 和 LENGTH_SHORT用于设置显示时长。
##如何使用
我们看一下如何使用:
|
|
###方法:
###属性:
###示例:
|
|
部局文件中rootlayout是framelayout并且添加了FAB(Floating action button),看一下FAB示例:
点击FAB查看结果:

程序没问题,但是对于用户体验来说并不太好,它应该向上移一些,如下图所示:
Having a CoordinatorLayout in your view hierarchy allows Snackbar to enable certain features, such as swipe-to-dismiss and automatically moving of widgets like FloatingActionButton.
我们在该系列文章的下一部分讨论CoordinatorLayout。

###配置Snackbar可选操作
我们可以使用额外的可选操作来配置snackbar,比如setActionTextColor 和 setDuration:
|
|
参考文档:
https://developer.android.com/reference/android/support/design/widget/Snackbar.html
###总结
在这部分文章中,我们讨论了Snackbar,它和TOAST很相似,但是它更灵活一些。Snackbar中可以定义action,当用户与屏幕交互时或者显示一段时间后会自动消失。
通过 CoordinatorLayout我们可以看到更多的effects 和 behaviours,在该系列文章中后续会讨论它。
在开发一款移动app时的一个事实是会有很多约束,比如硬件(CPU、RAM、Battery 等等)。如果你的代码设计不是很好,你会遇到一个非常让人头疼的问题:“Crash”,研究表明:
>
*应用崩溃时绝大多数应用使用者抱怨的问题。
此外
>
崩溃跟踪系统,帮助开发者能够直接的葱用户的设备收集每一个崩溃原因,是不是发现这个功能很特殊。目前最受欢迎的崩溃跟踪系统是 Crashlytics和Parse Crash Reporting,这两个系统都是完全免费的。开发者可以免费的集成他们在自己的应用中。不论什么时候app崩溃了,整个bug信息将会发送到后台,允许开发人员用最简单的方式去解决这些bug。通过这个方法,你可以在短时间内迭代一款不会影响正常使用的应用。
然而,提供崩溃信息收集的厂商收集这些崩溃信息同时也收集了用户信息,这可能让引起大公司担心用户隐私。
所以,这儿有没有崩溃信息跟踪系统可以让我们搭建在自己的服务器上?那么就不存在泄漏用户隐私的担忧了。当然有了,并且这个系统提供了非常简单的搭建方法。在这里我们来介绍下Application Crash Reporting on Android (ACRA),一个库允许Android应用自动地发送崩溃信息到自己的服务器。
下面将会介绍如何去搭建。
服务器端是一个先决条件,让我们先从搭建服务器端开始。
由于ACRA设计的很好并且很受欢迎。它允许开发者开发自己的服务器系统,并且现在我们可以看到很多这样的系统。即便如此我觉得最好的是Acralyzer,这个也是由ACRA团队研发。Acralyzer工作在Apache CouchDB,所以
这里没有必要安装除了CouchDB以外的软件。
Acralyzer是一个功能相当齐全的后端崩溃跟踪系统。来自不同原因的相同堆栈轨迹将会被分组成一个单一的问题。如果你解决了所有问题,你可以非常便捷的关闭Acralyzer服务,并且这种关闭服务的操作时实时的,我发现系统唯一的缺点是它的ui让人感到不舒服,但是谁会在乎这个?它是为开发者开发的。
安装起来也很简单,下面将介绍如何在Ubuntu安装Acralyzer。
打开命令窗口,开始安装couchdb
>
*apt-get install couchdb
Test the installation with this command:
测试是否安装成功。
>
*curl http://127.0.0.1:5984
如果正确安装,会显示如下:
>
*{“couchdb”:”Welcome”,”version”:”1.2.0”}
编辑etc/couchdb/local.ini允许我们通过外部IP(默认的访问会通过127.0.0.1)去访问CouchDB。仅仅改变两行实现这个功能:
>
;port = 5984 ;bind_address = 127.0.0.1
改变为
>
port = 5984 bind_address = 0.0.0.0
在同一个文件夹下,你需要添加username/password作为管理员账户。找到这一行(应该会在文件末尾)
>
*[admins]
下一行添加username/password 形式为username = password,比如:
>
*[nuuneoi = 12345]
请不要对在这里书写明文密码感到担心,一旦CouchDB重启后,你的密码将会自动地散列,并且将会是不可读的,
保存你刚刚编辑的文件同时通过命令行重启hashed:
>
*curl -X POST http://localhost:5984/_restart -H”Content-Type: application/json”
从现在起,你将可以通过浏览器访问CouchDB。这个web服务我们称之为Futon,一个CouchDB UI管理后台。在你的浏览器中打开这个地址。
>
*http://
:5984/_utils
让我们开始吧,Futon。
首先,通过你之前设置的管理员账号登陆这个系统。
现在我们开始安装一个acro-storage (Acralyzer’s Storage Endpoing).在左边的菜单,点击Replicator,然后填写远程存储改为本地存储的表单。
>
*from Remote Database: http://get.acralyzer.com/distrib-acra-storage to Local Database: acra-myapp
点击Replicate然后等待,知道这个过程结束。
下一步安装Acralyzer通过同样的方法,但是参数是不同的。
>
*from Remote Database: http://get.acralyzer.com/distrib-acralyzer to Local Database: acralyzer
点击Replicate安装。
如果你操作正确,系统将会有两个数据库,acra-myapp 和 acralyzer。
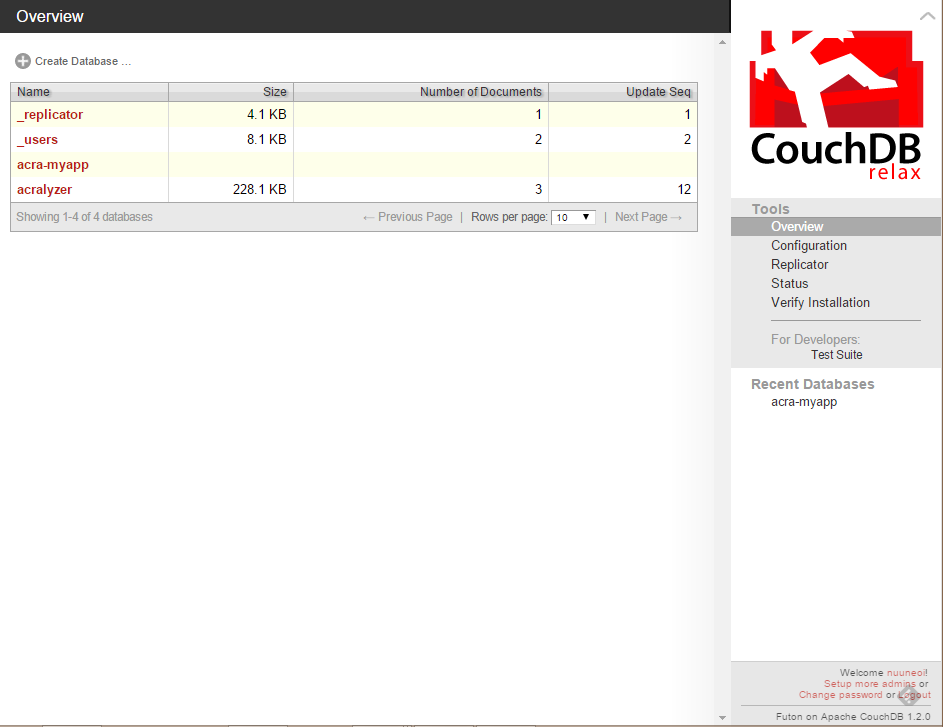
我门就快大功告成了,下一步,我们需要为这个客户端创建一个用户,打开浏览器,然后打开这个网址:
>
*http://
:5984/acralyzer/_design/acralyzer/index.html
填写你想要的Username/Password,然后点击Create User,这些信息将会出现。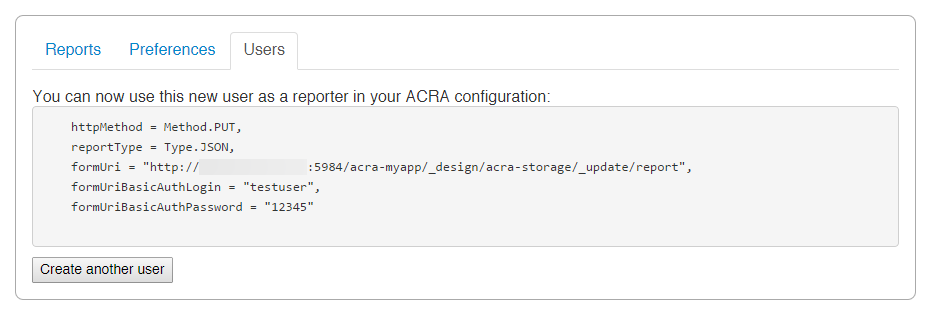
复制这些信息,然后粘贴到你的文本编辑器,我们可能会用这个在客户端设置。
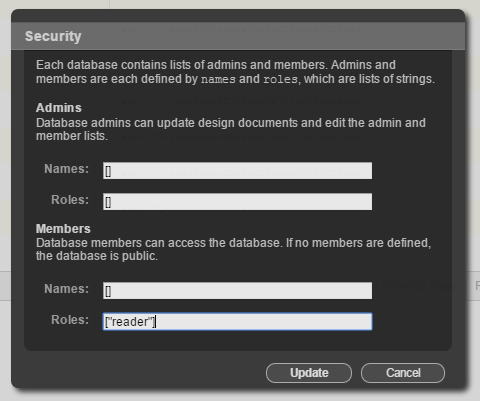
最后一件事是限制访问权限来保护在acra-myapp里面的数据,进入acra-myapp然后点击Securities,填写用户角色分配;
>
*[“reader”]
完工!
在这些结束后,你可以通过同一个网址访问这个控制台,去Admin选项卡,并选择Users。
>
*[http://
:5984/acralyzer/_design/acralyzer/index.html
请注意acro-myapp只能够为一款应用服务。以防你想为另外一款应用创建一个后台,请通过同样的过程复制另外一个acro-storage,但是改变本地数据库名为acra-
如果在系统中有不止一款应用,在Acralyzer的仪表盘中将会有一个下拉列表,让我们去选择看哪一个的问题。你可以试一试。
在客户端设置ACRA。
在客户端中设置ACRA很简单,首先,在你的 build.gradle里添加ACRA的依赖配置信息。
>
*compile ‘ch.acra:acra:4.6.1’
同步你的gradle文件,然后创建一个自定义Application类,但是不要忘记在AndroidManifest.xml中定义这个Application类。(我假设每一个Android开发者不会忘记这么做)。
在你创建的自定义的Application类中添加 @ReportCrashes注解。
|
|
现在我们复制服务器端生成的信息,并且像下面那样粘贴到@ReportsCrashes中。
|
|
最后一步,不要忘记添加在AndroidManifest.xml网络访问权限,否则ACRA可能无法发送这些日志信息到你的服务器上。
>
*
恭喜,现在所有的配置都已经完成,ACRA可以正常的工作,帮助你收集崩溃日志信息,从而你可以快速解决应用出现的问题。
##测试##
现在我们通过在Activity中强制一些崩溃来做一些测试,例子如下:
|
|
运行你的应用,然后改变崩溃的原因,再运行一次。查看你的仪表盘,你将会看到这些发送到后台的bug。

每一个bug来自不同用户不同时间,并且这些报告被分组了。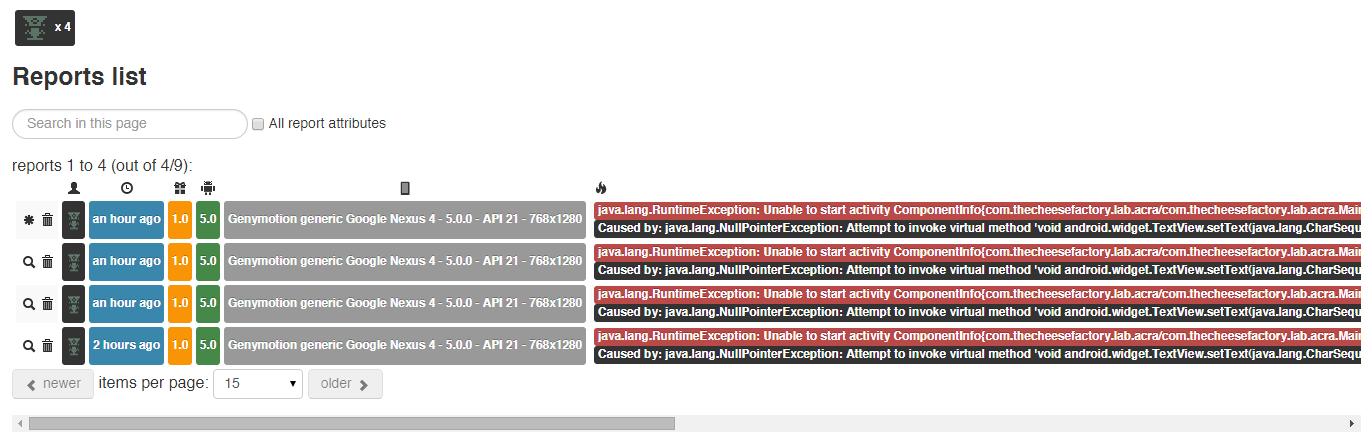
仔细看看这些报告信息,你将会发现他们都是完整的崩溃信息。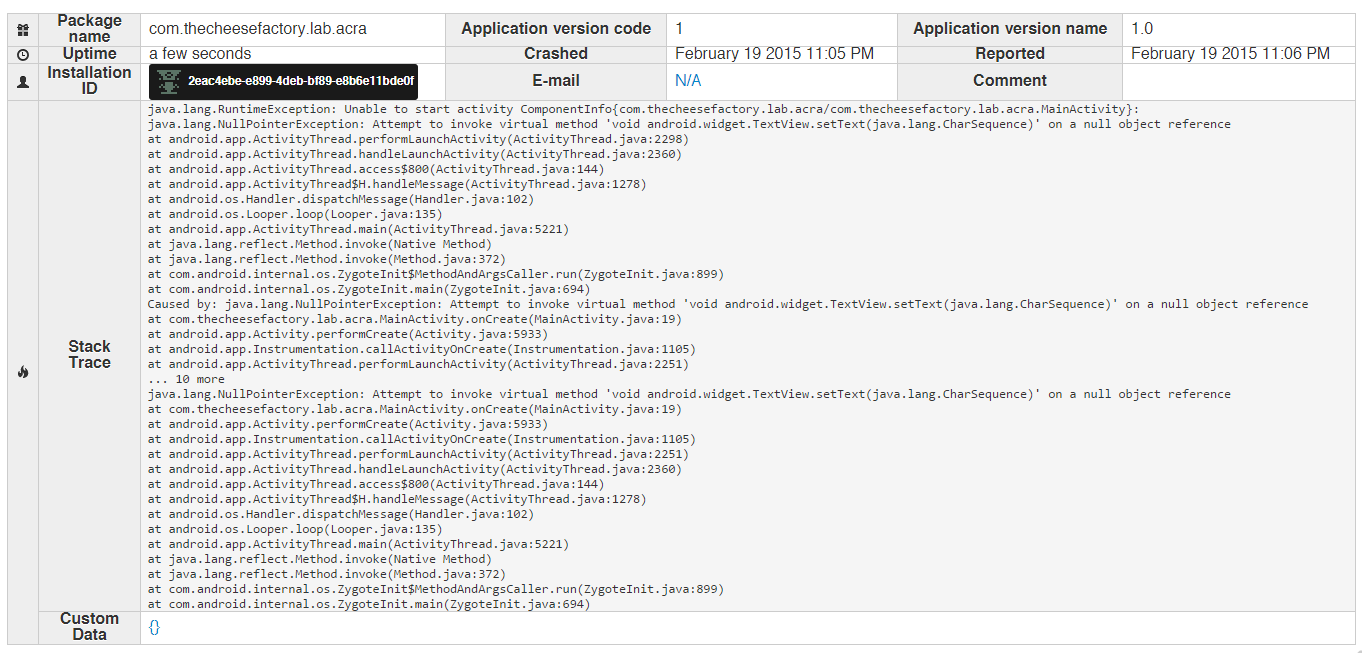
并且非常多的信息,足足有7页。
如果你修复这些bug后,你可以关闭这个问题,通过简单的点击在页面中高亮显示的”bug”图标,
希望这篇文章对你们有用,特别是对于一些需要应用崩溃信息收集但是却担心隐私信息的大公司可以来使用这个系统。
事实上ACRA还有许多其他特性,比如:当一个月崩溃时显示Toast 或者 popup 来报告这些信息。你可以在ACRA网站上发现这些选项。
Acralytics也一样,这里有许多其他特性可以使用,比如,你可以设置一个服务器来发送邮件给我们。
下一篇博客再见。
如果你之前用eclipse开发过Android app的化,转到android studio的第一反应也许就是:”编译速度有点慢”. 表现的最明显的一点就是,当我使用eclipse开发的时候,选中了auto building.这个时候
我更改了几个字符,eclipse会速度非常快的编译出一个新的apk. 而android studio使用gradle编译,每次编译,即便是更改的代码量很少,也会按照预先设置的task的顺序,依次走完编译的各项流程.所以
这点就让人很痛苦. 然而问题总还是要被解决的,作者曾经亲眼看到过使用android studio仅仅用了2.5秒就编译完毕(在代码更改很少的情况下). 现在把如何优化gradle编译速度的方法记录在此,希望可以
帮助到广大的同行们.
gradle现在最新的版本是2.4, 相比较之前的版本, 在编译效率上面有了一个非常大的提高,为了确保你的android项目使用的是最新版的gradle版本,有两种方法可以使用,下面依次进行介绍
在你的项目gradle文件内(不是app里面的gradle文件), 添加一个task, 代码如下:
|
|
然后打开terminal, 输入./gradlew wrapper, 然后gradle就会自动去下载2.4版本,这也是官方推荐的手动设置gradle的方法(http://gradle.org/docs/current/userguide/gradle_wrapper.html)
这种方法需要你去手动去gradle官网下载一个zip包,解压缩后,打开android studio 设置界面的Project Structure. 然后手动添加你解压缩后的gradle的磁盘路径即可,可以参考如下的图片
有一点需要注意的是,这种设置方法仅适用于在你的项目中使用gradle wrapper进行编译打包的操作(就是android studio默认需要的东东).如果你想使用gradle做其他的事情,请出门左转,去gradle官网(http://gradle.org)
通过以上步骤,我们设置好了android studio使用最新的gradle版本,下一步就是正式开启优化之路了. 我们需要将gradle作为守护进程一直在后台运行,这样当我们需要编译的时候,gradle就会立即跑过来然后
吭哧吭哧的开始干活.除了设置gradle一直开启之外,当你的工作空间存在多个project的时候,还需要设置gradle对这些projects并行编译,而不是单线的依次进行编译操作.
说了那么多, 那么怎么设置守护进程和并行编译呢?其实非常简单,gradle本身已经有了相关的配置选项,在你电脑的GRADLE_HOME这个环境变量所指的那个文件夹内,有一个.gradle/gradle.properties文件.
在这个文件里,放入下面两句话就OK了:
|
|
有一个地方需要注意的是,android studio 本身在编译的时候,已经是使用守护进程中的gradle了,那么这里加上了org.gradle.daemon=true就是保证了你在使用命令行编译apk的时候也是使用的守护进程.
你也可以将上述的配置文件放到你project中的根目录下,以绝对确保在任何情况下,这个project都会使用守护进程进行编译.不过有些特殊的情况下也许你应该注意守护进程的使用,具体的细节参考http://gradle.org/docs/current/userguide/gradle_daemon.html#when_should_i_not_use_the_gradle_daemon
在使用并行编译的时候必须要注意的就是,你的各个project之间不要有依赖关系,否则的话,很可能因为你的Project A 依赖Project B, 而Project B还没有编译出来的时候,gradle就开始编译Project A 了.最终
导致编译失败.具体可以参考http://gradle.org/docs/current/userguide/multi_project_builds.html#sec:decoupled_projects。
还有一些额外的gradle设置也许会引起你的兴趣,例如你想增加堆内存的空间,或者指定使用哪个jvm虚拟机等等(代码如下)
org.gradle.jvmargs=-Xmx768m
org.gradle.java.home=/path/to/jvm
如果你想详细的了解gradle的配置,请猛戳http://gradle.org/docs/current/userguide/userguide_single.html#sec:gradle_configuration_properties
最后一个要介绍的是incremental dexing, 这个功能目前还在试验阶段,android studio默认是关闭的, 作者个人是非常推荐的,程序员就是爱折腾啊.
开启incremental dexing也是非常简单的,就是在app级别的buid.gradle文件中加入下面的代码:
|
|
感性您的阅读,希望这边文章可以对您有所帮助. 如果您有好的建议或者意见请联系我
在上一篇的博文(Gradle tip #2 : Tasks)中,我们讨论了gradle构建的基本单位Task. 并且介绍了构建过程的各个阶段及其生命周期.而本文会重点介绍gradle的语法.只有具备了gradle
的相关语法知识,才会大幅度的提高对于阅读、学习或者编写gradle脚本的效率,正所谓”磨刀不误砍柴工”是也.
gradle 是groovy语言实现的构建工具. groovy是运行在jvm平台的一门敏捷开发语言.其语法和java有诸多类似之处,然而其具备一些java没有的概念需要读者细细体会.下面会详细的介绍
groovy的基本语法,当然如果您已经对groovy的语法有了一定的了解.可以直接跳过这一小节.
闭包是groovy中最重要的概念之一. 简单地说闭包(Closures)是一段代码块. 这个代码块可以接受参数并具有返回值. 有一点要非常注意的是, 闭包往往不是在需要使用的时候才写出来
这么一段代码(就像Java的匿名类那样), 通过def 关键字可以声明一个变量代表一个闭包,然后在需要的时候直接使用该变量即可,多说无益,请看如下的例子:
|
|
output: Hello world!
|
|
output: Hello world!
|
|
output: Hello world!
|
|
output: my string : 21
|
|
output: my string : 21
|
|
output: Hello world!
|
|
output: Hello from MyClass!
在groovy中,将闭包作为参数传递进函数,是将逻辑进行分离解耦的重要手段.在上述的例子中,我们已经尝试了如何将闭包作为参数进行传递.下面我们总结一下传递闭包的方法:
myMethod(myClosure)
myMethod myClosure
myMethod {println ‘Hello World’}
myMethod(arg1, myClosure)
myMethod(arg1, { println ‘Hello World’ })
myMethod(arg1) { println ‘Hello World’ }
细心的朋友们是不是觉得上述的六种用法中,第三条和第六条很眼熟?很像gradle中的scripts了?
在知道了groovy的基本语法(尤其是闭包)之后,下面我们就以一个简单的gradle 脚本作为例子具体感受一下:
|
|
结合前文的例子,我们可以很容易的理解到,buildscript是一个接受闭包作为参数的函数,这个函数会在编译的时候被gradle调用.这个函数的定义就类似于:def buildscript(Closure closure). 而allprojects 同理也是一个接受闭包作为参数的函数.
那么问题来了,这些函数具体会在什么时候被gradle调用呢?要回答这个问题就需要介绍另一个知识点:Project
在这里,我觉得逐句翻译作者查阅文档的步骤没有太大的意义,我自己总结了一下作者的概念如下:
理解gradle配置文件中的script如何调用的关键就是理解project的相关概念.在gradle执行某个”任务”的时候,会按照各个task的依赖关系来依次执行. 而执行这些task的对象就是Project.说的在通俗一些,project就是你希望gradle为你做的事情,而要完成这些事情,需要将事情分成步骤一步一步的做,这些步骤就是task.
通过前文的学习,我们已经很清楚的了解到scipt block就是一段接受闭包的函数,这些函数会被Project调用,默认的情况下,gradle 已经准备
好了很多script用于我们对项目进行配置,例如buildScript{} … … 当然你也可以自己写出符合规范的task来在编译的过程中被调用.
下面我们先看一下Android Studio中默认的script:
|
|
按照我们已经有的知识,上面的脚本说明有一个名称为android的函数,该函数接收闭包作为参数,然而其实在Gradle的文档中是不存在这个函数
的. 那么android脚本怎么会出现在这里呢? 答案就是最上面的apply plugin:
‘com.android.application’.这个插件提供了android构建所需要的各种script.
既然gradle官方的文档中没有android相关的script信息,那我们该怎么查阅呢? 您可以去官方的android网站上查阅,如果懒得找的话请点击这个链接:https://developer.android.com/shareables/sdk-tools/android-gradle-plugin-dsl.zip
您下载了前文连接的文档后,可以发现有一个html格式的文档的名字是AppExtension, 这个文档主要就是介绍了Android configuration blocks. 即在gradle官方文档中没有的关于Android 配置的各种gradle script都可以在这里进行查阅(几个例子):
1、 compileSdkVersion 在文档中的描述是Required. Compile SDK version. 即这个脚本是gradle进行Android构建之必需,并且这个脚本是
是用来描述编译的时候使用的sdk版本.
2、buildToolsVersion在文档中的描述是Required. Version of the build tools to use. 即该脚本是构建之必需,其用于告诉gradle使用
哪个版本的build tools
3 … … (详细情况请参阅文档吧:))
有了前文的学习作为基础,我们已经了解了gradle语法以及android 插件的脚本查阅方法. 那么接下来我们实际运用这些知识,自定义的对我们
的Android项目进行一些配置. 在上述的AppExtension文档中,我查阅到了一个脚本的名字是testOptions. 这段脚本代表的是TestOption class
调用,TestOption class里有三个属性:reportDir、resultsDir 和unitTests. 而reportDir就是测试报告最后保存的位置,我们现在就来改一下
这个地方.
|
|
在这里,我使用了”$rootDir/test_reports”作为测试结果的储存位置, $root 指向的就是项目的根目录.现在如果我通过命令行执行
./gradlew connectedCheck. gradle就会进行一系列的测试程序并且将测试报告保存在项目根目录下的test_reports文件中.
注意一点的是,这个关于测试的小例子,别用在你真是的生产环境中,尽量保持你项目结构的”清洁”
之前面试的时候,面试官问题threadlocal怎么用?当时就懵逼了,只是见过,却不知道如何使用。
提到ThreadLocal,有些Android或者Java程序员可能有所陌生,可能会提出种种问题,它是做什么的,是不是和线程有关,怎么使用呢?等等问题,本文将总结一下我对ThreadLocal的理解和认识,希望让大家理解ThreadLocal更加透彻一些。
ThreadLocal是一个关于创建线程局部变量的类。
通常情况下,我们创建的变量是可以被任何一个线程访问并修改的。而使用ThreadLocal创建的变量只能被当前线程访问,其他线程则无法访问和修改。
创建,支持泛型
ThreadLocal<String> mStringThreadLocal = new ThreadLocal<>();
set方法
mStringThreadLocal.set("droidyue.com");
get方法
mStringThreadLocal.get();
|
|
在当前目录新建一个Git代码库
$ git init
新建一个目录,将其初始化为Git代码库
$ git init [project-name]
下载一个项目和它的整个代码历史
$ git clone [url]
Git的设置文件为.gitconfig,它可以在用户主目录下(全局配置),也可以在项目目录下(项目配置)。
显示当前的Git配置
$ git config —list
编辑Git配置文件
$ git config -e [—global]
设置提交代码时的用户信息
|
|
添加指定文件到暂存区
$ git add [file1][file2] …
添加指定目录到暂存区,包括子目录
$ git add [dir]
添加当前目录的所有文件到暂存区
$ git add .
添加每个变化前,都会要求确认,对于同一个文件的多处变化,可以实现分次提交
$ git add -p
删除工作区文件,并且将这次删除放入暂存区
$ git rm [file1][file2] …
停止追踪指定文件,但该文件会保留在工作区
$ git rm --cached [file]
改名文件,并且将这个改名放入暂存区
$ git mv [file-original][file-renamed]
在正式开始之前这里要着啰嗦一下,进来的同学一定要看,在申请应用的时候要填一个签名,这个签名是由应用的签名文件keystore决定的,那么你在填这个签名的时候,一定要把你的应用用正式的keyStore生成apk,安装到手机,然后用微信提供的获取应用签名的apk工具获取你应用的签名,然后这会生成的这个签名才是正确的,千万记得,不要使用dubug的ketStore测试,不然后面虽然可以修改,修改了后要审核,但是审核也是需要时间的,会很麻烦。
还有一点,你在测试微信分享的时候可能会直接在Eclipse好或者Studio运行项目,那样使用的肯定是dubug的keyStore了,这样分享的时候会被微信拒绝,微信会生成缓存,就算你这会换了正式的keystore来分享显示的还会是被微信拒绝,就算重启微信重启手机也不管用,那你就要清空微信的数据了;很多东西是不是丢了?好吧,啰嗦够了,正式进入主题。
今天会提供如果实现微信分享,并且对怎么成功接受回调结果做一个详细的介绍和教程,有回调结果失败的同学,往下看吧
使用UIL时,如果只是简单加载一个图片的bitmap,可以使用SimpleImageLoadingListener方法,而不是ImageLoadingListener。
|
|
Activity或Fragment中对adapter.updateDataSet(data);时,notifyDataSetChanged的操作放在adapter的updateDataSet方法内执行。
#不对0x80以上的字符进行quote,解决git status/commit时中文文件名乱码
git config --global core.quotepath false
http://xstarcd.github.io/wiki/shell/git_chinese.html
Android 开发中类、方法、变量、资源等命名规则。
键盘相关操作方法
未自动化前安卓开发总是避免不了这样的工作流程:
实现了这套自动化发布后,工作流程被简化成:
Tag提交后Travis CI会自动编译代码,生成APK文件并分发到Github和fir.im,Github和fir.im中会保持Tag的描述信息,分发完成后会有邮件通知所有参与测试的人员。而作为开发人员,只需要专注于对代码打好一个Tag就可以了。
整个流程看似做了不少工作,其实体现在Travis CI只有数行指令而已,以下逐一讲解: